| |
HR 資料治理怎麼做?建立單一人才資料模型的四個步驟 |
作者:育碁顧問群 | 日期:2026/06/10 |
|
一、報表做得出來,卻不敢拿來輔助決策
實務上常看到一種情況:企業裡的人才資料其實累積得不算少,但真正能讓主管放心拿來輔助決策的,卻往往不多。
人才資料散落在人事、績效、學習、職能評量等多個系統,各自累積多年,欄位定義也多不一致。資料「有」,但彼此對不齊,整合分析時就只能靠人工反覆核對與判斷。
以「職等」為例:人事系統叫「職等」、績效系統可能叫「職級」、另一套又叫「職務等級」,三者的編碼規則還不相同。HR 想合併分析時,光是把這些欄位對應起來就要耗費大量人力,且容易出錯——這正是資料分析做不準的根因。要解決它,得先回到「資料治理」這件事。
二、什麼是 HR 資料治理?它和「資料收集」不一樣
資料治理(Data Governance)指的是:為人才資料的定義、品質、一致性與可追溯性,建立一套明確的規則與責任歸屬。它要處理的,已經不只是「我們手上有沒有這筆資料」這個層次,更包括確保這筆資料在需要被使用時,是否可信、是否查得到來源、整合應用時的一致性可以確保。
也因此,比起把資料累積得夠多,資料治理更在意的是:當這些資料被拿來使用時,能不能維持一致、可信,並且查得到來源。
下表對照「只做資料收集」與「落實資料治理」的差異:
| 比較維度 |
只做資料收集 |
落實資料治理 |
| 欄位定義 |
各系統自訂,彼此不一 |
全公司統一定義與代碼 |
| 資料來源 |
同一人多份主檔並存 |
員工主檔單一可信來源 |
| 跨系統使用 |
靠人工對應與彙整 |
依關聯模型自動流通 |
| 對 AI 的意義 |
AI 難以判讀、AI產出的分析存疑 |
AI 可正確理解與推論 |
而資料治理落地後的第一個具體產物,就是一套「單一人才資料模型」。
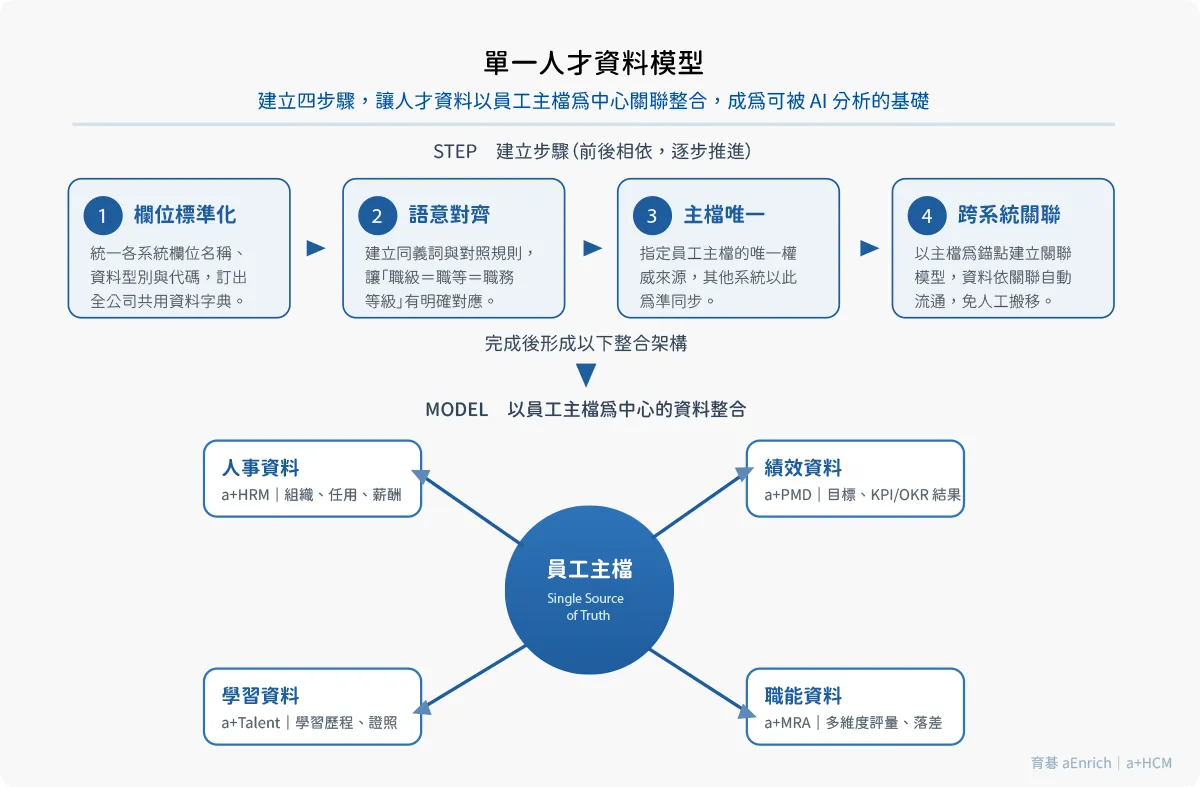
三、建立單一人才資料模型的四個步驟
單一人才資料模型,指的是讓同一位員工在所有系統中,都對應到一致的定義與唯一的主檔。建立它可分為四個步驟,前後相依、逐步推進:
步驟一|欄位標準化
為什麼:欄位定義不一致,是跨系統分析失準的第一個源頭。
怎麼做:盤點各系統的人才欄位,統一名稱、資料型別與代碼表(如職等、部門、職務代碼),訂出全公司共用的「資料字典」,作為日後所有系統的共同依據。
步驟二|語意對齊
為什麼:名稱相同不代表意義相同,名稱不同也可能其實是同一件事。
怎麼做:建立同義詞與對照規則,讓「職級=職等=職務等級」這類語意衝突有明確的對應關係,避免 AI 把同一個概念誤判為多個不同的變數。
步驟三|主檔唯一(Single Source of Truth)
為什麼:同一員工存在多份主檔時,AI 無從判斷哪一份才是正確的。
怎麼做:指定員工主檔的唯一權威來源,其他系統的人員資料以此為準同步,而不是各自維護一份,從源頭杜絕版本衝突。
步驟四|跨系統關聯
為什麼:資料能被分析的前提,是各維度資料之間有明確的關聯結構。
怎麼做:以員工主檔為錨點,建立人事、績效、學習、職能等資料之間的關聯模型,讓資料能依關聯自動流通,而非靠人工搬移。
在系統層面,這套模型的關鍵在於是否有「共用的資料底層」。以育碁 a+HCM 為例,各應用模組共用同一個 a+Core 核心共用底層,人事、績效、學習、職能評量在設計上即共用一致的人才資料定義,因此不需要事後再做大規模的資料整合工程。這屬於系統既有的架構特性;至於後續要把整理好的資料導入哪一種 AI/LLM 應用,則是企業可依自身治理策略進一步規劃的方向。其中,作為後續所有人才分析起點的人員主檔,即由 a+HRM 人資管理 集中維護,確保人事、組織與任用資料有單一可信來源。
延伸了解:想了解如何應用同一資料庫架構,為企業打造 AI-Ready Data,可參考育碁 a+HCM Total Solution。
四、治理到位後,HR 能回答哪些以前答不出的問題
示意情境(說明用,非實際客戶):假設一家企業完成了上述資料治理——員工主檔唯一、欄位定義跨系統一致——HR 與主管就有機會用同一套可信資料,回答這類過去難以處理的問題:
- 高績效員工,在哪些職能維度上有共同特徵?
- 哪些學習路徑最能縮短職能落差,並在後續績效上看到變化?
- 培訓資源投入在哪個領域,對組織目標的幫助最明顯?
這些問題在資料各自為政時,往往很難得到可信的答案;等到資料治理到位、各系統口徑一致之後,才有機會被系統性地分析與比對。
五、導入前,先問自己這三個問題
在投入工具或 AI 之前,建議先用三個問題檢視現況:
- 員工主檔是否唯一?同一人是否存在多份並存的紀錄?
- 關鍵欄位(職等、部門、職務)的定義,是否跨系統一致?
- 系統之間的資料,是靠人工搬移,還是能依關聯自動流通?
若三題中有任一題答「否」,代表資料治理仍有缺口。此時優先補治理、再談 AI,會比急著選工具更務實。
導入順序上,建議可先從人事主檔的標準化與唯一化著手,再逐步串接績效、學習與職能資料,最後才將整合好的資料導入 AI 應用。這樣的順序,讓每一階段都有可驗證的成果,而非一次到位的大工程。
六、為何選育碁 a+HCM 作為 AI-Ready Data 的架構基礎?
前面談的單一資料模型、主檔唯一與跨模組關聯,落到系統面,仰賴的是一個共用的資料底層把它們撐起來。育碁 a+HCM Total Solution 以「a+Core 核心共用底層」為基礎,HRM 與 HRD 各模組共用同一套人才資料定義,本身即具備本文所談的 AI-Ready Data 架構特性。
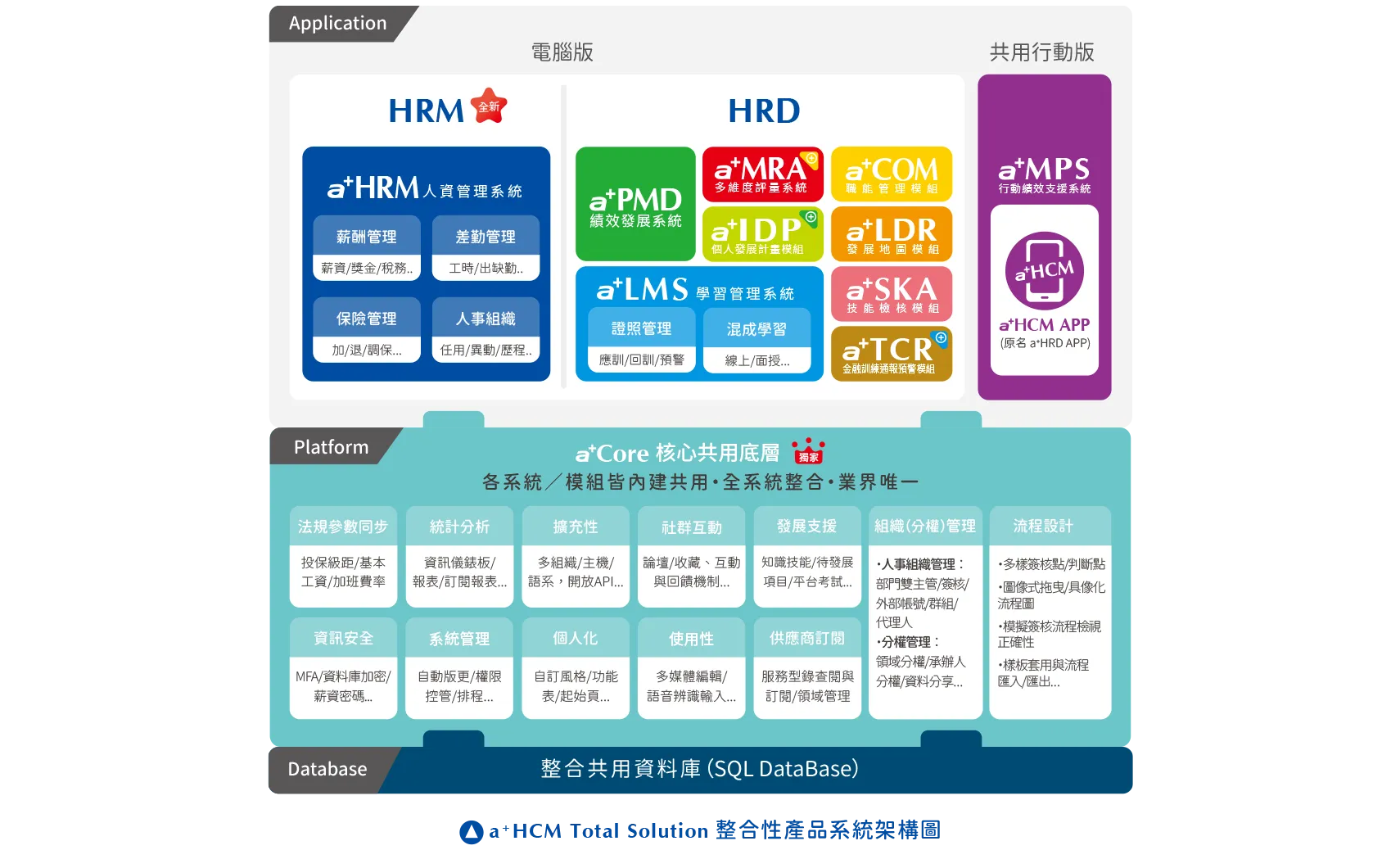
圖:a+HCM Total Solution 整合性產品系統架構 — 以 a+Core 核心共用底層整合 HRM 與 HRD 模組
單一資料模型,原生跨模組整合:a+HRM、a+PMD、a+Talent(含 LMS)、a+MRA 等模組共用一致的人才資料定義,跨模組分析不需另做大規模的資料整合工程。
共享資料庫架構,打底 AI-Ready Data:同一資料庫架構可強化資料一致性,為後續 AI 與預測性分析奠定基礎。
現代化技術與資安規格:a+HCM 8.2 即採用 Microsoft .NET 10 (Visual Studio 2026)技術架構開發 與 支援SQL 2025,育碁團隊通過 ISO/IEC 27001:2022 認證,兼顧效能、擴充與合規。
持續版更,跟上法規與技術:自研 HRM+HRD 系統每年穩定投入 超過4,000 萬以上進行版本升級,並以訂閱機制同步法規更新。
了解整體架構可參考 a+HCM Total Solution;共用底層的設計細節見 a+Core 核心共用底層。
結語:讓人才資料先就緒,AI 才能就位
AI 時代的人才決策,終究要從一份可信任的資料開始。對多數企業而言,資料治理是讓 AI 能真正落地的前置工作,值得在導入 AI 之前就一步步把它做好。







